

 I recently dusted off an artificial neural network project, now published at https://bitbucket.org/egrange/daneuralnet/. This is a subject I’ve been dabbling on and off since the days of 8 bit CPUs.
I recently dusted off an artificial neural network project, now published at https://bitbucket.org/egrange/daneuralnet/. This is a subject I’ve been dabbling on and off since the days of 8 bit CPUs.
The goals of the project are twofold: first experiment with neural networks that would be practical to run and train on current CPUs, and second experiment with JIT compilation of neural networks maths with Delphi.
TensorFlow and Python are cool, but they feel a bit too much like Minecraft, another sandbox of ready-made blocks 😉
The repository includes just two classic “demos”, and XOR training one, and another with the MNIST digits which is mostly useful for benchmarking maths routines, the dataset itself .
There are dependencies to the DWScript code base (for JIT portions), and the code is intended for Delphi 10.3 (uses modern syntax). This will also serve to kick-start the 64bit JITter for DWScript (stuck in limbo) and a SamplingProfiler 64bit version (stuck in limbo).
The video below shows the output of the Neural Network while training to learn the XOR operator. Input values are the (x, y) coordinates of the image normalized to the [0..1] range.
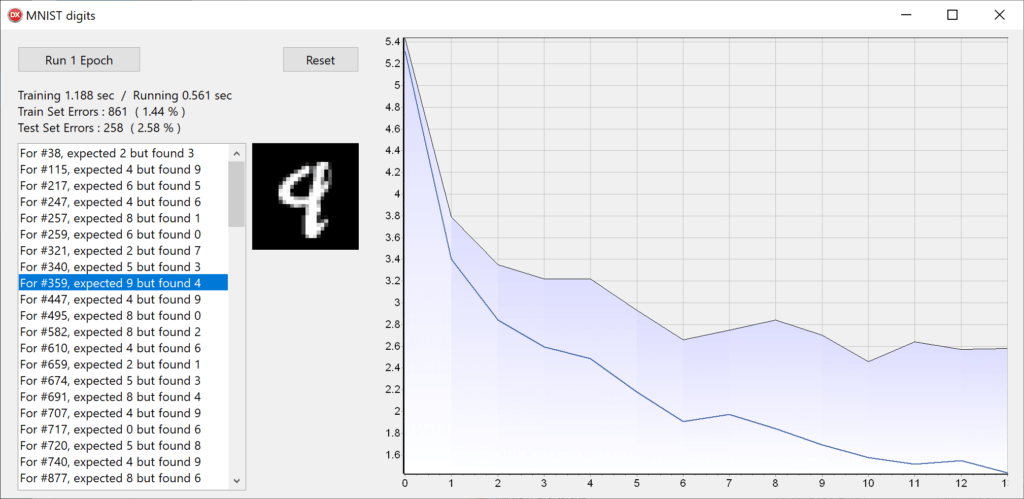
The MNIST dataset demos trains a small 784-60-10 network, charts the progress and allows to check digits for which the recognition failed. Training time is over the whole 50k samples data set using Stochastic Gradient Descent, using a single CPU core.
What is the actual performance difference between Win32 JIT and Win64 asm of the current version?
IIRC unrolling the loop – as JIT does, but x86_64 asm doesn’t – is not a huge benefit on modern CPUs. On the contrary, less code may help the CPU opcache be more efficient – the better being if the loop can be within the CPU opcache lines.
Did you check https://github.com/joaopauloschuler/neural-api ?
This is a nice Open Source library by JP, with some proven asm to look upon.
Not sure about Win32, but for matrix-vector multiplication, vs the scalar SSE code generated by Delphi 10.3 (with excess precision off, but on a nested loop), my current best JIT’ed code is up to 25x faster on an AMD Ryzen, and up to 2x faster than OpenBLAS which has a similar-looking AVX/FMA kernel.
Nope, I had not found it in a quick search on Delphi / Pascal neural nets. Looks interesting indeed!