

 For a few weeks now, an experimental JIT compiler has been available in the DWScript SVN for 32bits code. A more detailed article into the hows and whats and WTFs will come later.
For a few weeks now, an experimental JIT compiler has been available in the DWScript SVN for 32bits code. A more detailed article into the hows and whats and WTFs will come later.
Consider this article as an extended teaser, and a sort of call for test cases, benchmarks and eyeballs on the source code.
Following benchmarks were compiled in XE2 with full optimization, no stack frames and no range checking. Absolute values aren’t meaningful, just consider them relatively.
Mandelbrot fractal
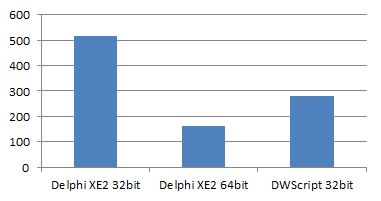 (lower is better)
(lower is better)
Delphi XE2-32bit : 515
Delphi XE3-64bit: 162
DWScript JIT 32bit: 281
The JIT was initially tested on the Mandelbrot benchmark, so that’s one of the cases where JITing is almost complete, with the exception of the SetPixel() call.
SciMark 2
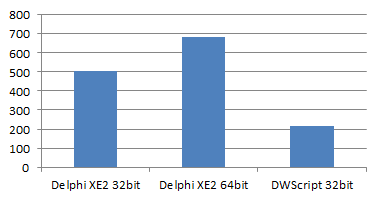 (higher is better)
(higher is better)
Delphi XE2-32bit : 507
Delphi XE3-64bit: 682
DWScript JIT 32bit: 215
Delphi version uses pointers, DWScript version was slightly updated to use dynamic arrays instead and JITting is partial at the moment.
The benchmark involves fairly large matrices, and DWScript use of Variant (16 bytes) rather than Double (8 bytes) means the data no longer fits in the CPU cache, which partly accounts for the poor showing of the JIT.
Array statistics
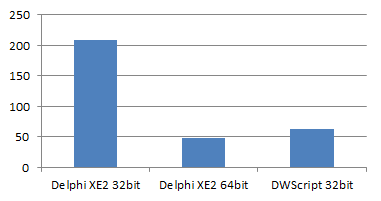 (lower is better)
(lower is better)
Delphi XE2-32bit : 208
Delphi XE3-64bit: 47
DWScript JIT 32bit: 63
This test measures of execution time of the following code (fully JITted), which computes the base values for common array statistics (range, average, deviation, etc.). The Delphi 32bit compiler really suffers because of Min/Max (despite having inlined them).
// "a" a floating point array of non-ordered values for v in a do begin s := s + v; s2 := s2 + v*v; mi := Min(mi, v); ma := Max(ma, v); end;
What next?
The DWScript JIT compiler relies on SSE2 to outperform the Delphi 32bit compiler, its current main limitations are:
- JIT centers around floating point and a limited subset of integer and Boolean operations, the rest isn’t JITted yet.
- Function calls aren’t JITted at the moment, and neither are a variety of other statements.
- The JIT works with the same data structures as the interpreted engine, that means script debuggers and everything else works on JITted code as if it was still interpreted, but that also means the basic data unit is still the 16 bytes Variant at the moment.
- The JIT register allocator is currently limited to floating point (ie. no integer or pointer allocations).
- DWScript Integer type is 64bit sized, so for 32bit values, Integer performance is lower than what Delphi 32 can do, even though the JIT can generate typically faster code for it than the Delphi 32bit compiler does for Int64.
The JIT also suffers against a 64bit compiler as there are 64bit CPU instructions (and registers) not accessible in 32bit mode, but a 64bit JIT should be able to go farther.
If you’re interested and want to help, I’m currently looking for benchmarks and test cases, if you have code that compiles in both Delphi and DWScript, particularly on integer maths (encryption, etc.) or object-oriented manipulations (graphs, trees…) that could help. You’re even allowed to have the Delphi version use pointers and other tricks, the comparison doesn’t need to be fair 😉
+1 Wow! Very very impressive!
First of all, thanks for your amazing job at DWS! Have you considered using DynASM (http://luajit.org/dynasm.html)? It´s the JIT engine behind LuaJIT and is considered one of the fastest JITters available, even outperforming V8 in most cases.
@gustavoLuaJIT gets a score of 601 in SciMark here, which places it somewhere in between Delphi 32 & 64bit compilers, so quite good indeed.
LUA llvm feedback is what scared from using llvm, but LuaJIT is indeed very fast, however it’s oriented towards a dynamic language, and it’s written in both ASM, C and LUA, so not easily reusable in a Delphi/pascal context.
What could be good is to have the benchmark values about plain interpreted DWS execution, for comparison.
I already posted my comments about your nice JITter in your previous post. They are still relevant to the current status – and you answered to them in your “What’s next” note above.
Great!
Yes, values for interpreted case are interesting!)
@Eric
>but LuaJIT is indeed very fast, however it’s oriented towards a dynamic language,
The message is clear… the spirit of Wirth must be vanquished and DWScript must move to dynamic typing!!! 😉
On a related note, there’s a project called HotPy that has been focused on bringing academic research focusing on optimzing *interpreters* to python. There’s some links off the main page to some of the techniques they’re using, and are hoping to improve the speed of the reference implementation CPython interpreter 3X and bring it up to 10X with JIT (of which the Pypy project already provides JIT in its own interpreter).
http://hotpy.org/
Maybe there’s something here that could help your already awesome efforts.
Honestly, your results put the lie to the drumbeat Embarcadero’s been making about “native” code and how it’s so much faster/better.
@Eric
The LUA dependency is only for pre-processing, so it is not needed in runtime. From the we page:
“There are no dependencies on Lua during runtime, i.e. when your code generator is in action”
@Joseph keep in mind that dynamic languages are fast in those cases because they execute what is actually strongly typed code, and the tracing compiler can rediscover that strong typing. IME code written to use dynamic typing performs usually very poorly on those tracing compiler as the JIT will make assumptions, which will be defeated, which needs constants re-JITting.
I don’t have the link handy, but there was a post about that on the Mozilla blogs sometime ago, that at some point when the tracing compiler is defeated too often, they now just turn off the JIT entirely and use only JS interpretation. For some sites this resulted in significant speed ups and memory usage reduction…
So while a dynamic language can perform well, that’s typically on code ported from a strongly typed language (like most benchmarks) or generated by a compiler (like GWT or Smart Mobile Studio), and then, that’s only because the tracing compiler allows to rediscover the implicit strong typing.
In SMS, what do you think of a new option for supporting http://asmjs.org at code emission?
Since we have some strong typing on the Object Pascal side, we may be able to emit the expected type information as annotations in the generated JavaScript.
@A. Bouchez Yep, that would be interesting, but I haven’t been able to find much beyond the spec about asm.js, is there an executable version of the compiler somewhere?
Also the codegen is already emitting “strongly typed” JS, so all that would be missing is the hitting, and avoiding the things asm.js doesn’t accept.