
 Work and processing classes are typically short-lived, created to perform one form of processing or another then freed. They can be simple collections, handle I/O of one kind of another, perform computations, pattern matching, etc.
Work and processing classes are typically short-lived, created to perform one form of processing or another then freed. They can be simple collections, handle I/O of one kind of another, perform computations, pattern matching, etc.
When they’re used for simple workloads, their short-lived temporary nature can sometimes become a performance problem.
The typical code for those is
worker := TWorkClass.Create; try ...do some work.. finally worker.Free; end;
This code can end up bottle-necking on the allocation/de-allocation when
- you do that a whole lot of times, and from various contexts
- you do that in a multi-threaded application and hit the single-threaded memory allocation limits
Spotting the Issue in the Profiler
If you use Sampling Profiler, you’ll know this because your profilling results wil look like this
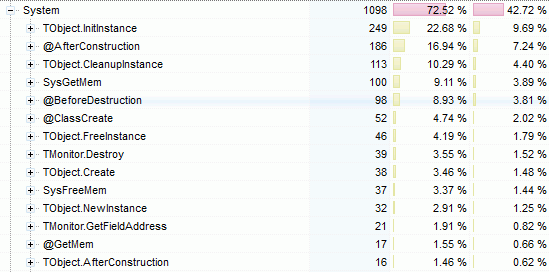
with TObject.InitInstance, @AfterConstruction, CleanupInstance, etc. up there, you just know you’re hitting the RTL object allocation/de-allocation overhead.
In the case of a single-threaded application, the RTL will often be the bottleneck, the memory manager is there but not anywhere critical. For more complex classes with managed fields, it will involve even more RTL time, and that will be in addition to your own Create/Destroy code.
In a multi-threaded application, you may see SysGetMem/SysFreeMem creep slowly toward the top spots.
Context Instance and Object Pools
A simple “fix” would be to create the work class once, then pass it around directly or in a “context” class (ie. together with other work classes). However, that isn’t always practical, either because the “context” isn’t well defined, or it would expose implementation details, or you just don’t to want to pass around a context parameter that would act as spaghetti-glue across libraries.
Another alternative is to use a full-blown object pool, but that usually involves a collection, and if you want to be thread-safe, it means some form of locking or a more complex lock-free collection, all kind of things which may not just be overkill, but could leave you with a complex pool that doesn’t behave much better than the original code for simple work classes.
Enter the mini object-pool, which is no panacea, but is really mini, thread-safe and might just be enough to take care of your allocation/de-allocation problem.


“What would really work in the above case is a template”
shameless plug (oldie but goldie):
http://www.dummzeuch.de/delphi/object_pascal_templates/english.html
Have you thought about a single linked list? Via InterlockedExchangePointer one could set the pointers to the next item thread safe. Such a list could grow as large as needed. But you’ll need an Item-Record to hold the pointer and the worker-object. Those items may also need some recycling effort (with a second list).
Single linked list (stack) isn’t as trivial to get right in a lock-free fashion (cf. http://www.boyet.com/articles/lockfreestack.html). If you can build the Next reference pointer into your work class, it can be efficient, but if you have to use an item-record, you’ll be adding extra management which could easily end up defeating all your gains.
Another issue is that even if it is lock-free, it won’t scale that well in multi-core environments, as all cores will be hitting the same cache line (the one with your stack top pointer), so you can still end up with implicit serialization at the memory level (the threadvar solution avoids that, and the hash solution statistically mitigates it).
IME the mini-pool approach is often enough, and it’s simple to get right, while more sophisticated approaches have more sophisticated pitfalls. And anyway, once your code is adapted to alloc & return to a pool, it’s easy to change the pool implementation, so you won’t have wasted time if you tried a mini-pool first 🙂
Very interesting.
Another option, especially if your object does not refer to any reference-counted class, is to define some record/object types with methods, allocated on stack, or within the main object instance.
What I like in your approach is that it started from real profiling, not from a vague guess.
Perhaps using “inline” functions may increase your code speed, especially with inlined asm for x86 platform.
But I’m not convinced that GetThreadID will be much faster than a threadvar.
Both will access the FS: segment: AFAIK GetThreadID uses a kind of “threadvar”, with a reserved TLS slot.
But we use this GetThreadID + hash table for the logging features of mORMot, with pretty amazing speed.
The GetThreadID approach main benefit is that you don’t have problems with freeing the pool. With a threadvar you have to include the pool(s) cleanup(s) as part of every thread’s cleanup, which isn’t very practical.
Using an interface to handle the cleanup automatically isn’t practical because you then need to handle the threadvar initialization for each thread… So that just exchanges a cleanup problem for an initialization one.
Hi Eric,
Nice post.
Just a hint what my approach is defining thread workers over piece of “undefined” data.
About data init, clear, free I use following approach when defining my thread workers queue:
aMsgSysQueueControl
.DedicatedThreads(1, True)
.Name(‘TMyTask ‘ + fContentManager.Name + ‘ Queue’)
.QueueSize(1000)
.NewTimer(1, 1000, OnTimerEvent)
.NewMessage(MSG_SET_CONTENT, SizeOf(Pointer), 100, OnInitContent, OnClearContent, OnFreeContent)
.ListenTo(Self, MSG_SET_CONTENT, OnContent);
At:
.NewMessage(MSG_SET_CONTENT, SizeOf(Pointer), 100, OnInitContent, OnClearContent, OnFreeContent)
This defines 100 bucks of pre-defined slots for “data” sized at Pointer, on which OnInitContent function is called. Of course pre-defined slots can grow on demand.
On finalization OnFreeContent is used.
Thread can be stopped before all data (or work) in the queue is processed, and this data can be complex and need external finalization).
Than everyone can post in the queue a peace of data or work without actually caring about initialization, clearing and finalization of the data, which tends to be fast using this approach.
For internal locking and thread-safety I use Conditional Variables used with Slim reader/writer locks. Good and very fast combination ran in user mode.