
 In a comment to the previous article on a case insensitive hash code, Stefan Glienke pointed to an approach used in Spring4D’s comparers, which is a delightful hack.
In a comment to the previous article on a case insensitive hash code, Stefan Glienke pointed to an approach used in Spring4D’s comparers, which is a delightful hack.
Rather than converting the string to a “proper lower case”, it converts the string to an “approximate lower case” using an “or $20”, which happens to be good enough for a hash on string identifiers.
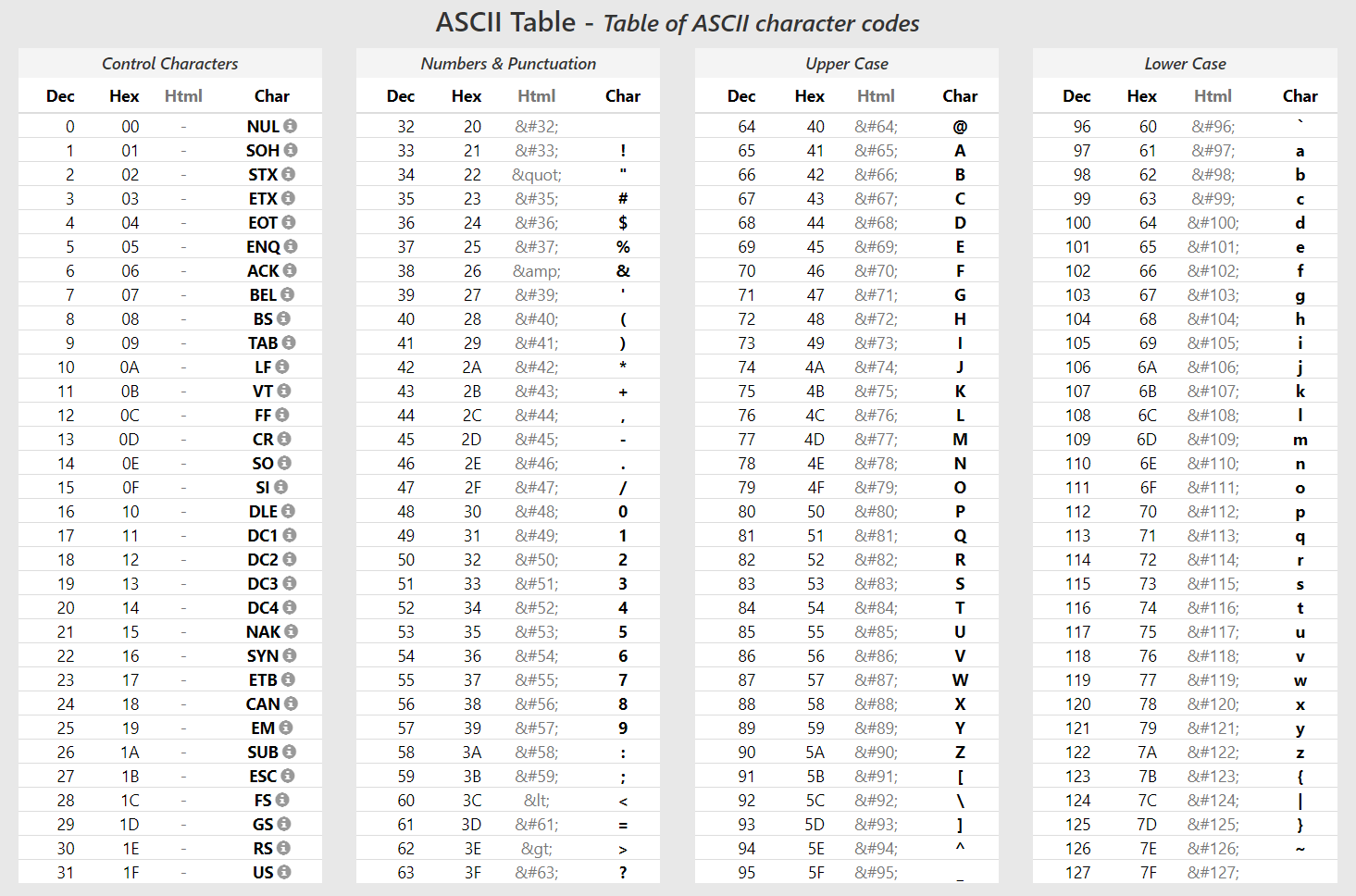
To figure the trick, one needs to check the ASCII Table.
ASCII Table
ASCII characters range in codes from 0 to 127, 7 bits, and were arranged in 4 groups of 32 characters ($20 in hexadecimal).
- Group $00 .. $1f is control characters, in typical strings you’ll only encounter TAB ($09), CR ($13) and LF ($10)
- Group $20 .. $3f is for numbers & punctuation, and a few operators
- Group $40 .. $5f is for upper case plus a few miscellaneous characters
- Group $60 .. $7f is for lower case plus a few miscellaneous characters
What’s happening
So what an “or $20” does is that on a character code is go from the control group to the numbers group, and from upper case group to lower case group. It leaves numbers & lower case groups characters unchanged.
Since we’re talking whole groups here, it’s not a “proper” lower case conversion:
- a TAB will become ‘)’, a CRLF will become ‘-*’
- an ‘@’ will become a backtick ‘`’, an ‘[‘ will become ‘{‘
- etc.
It’s not proper but it doesn’t matter
However when looking at identifier strings, there will be no control characters, so invalid control group conversions are moot. And in the upper case group, there are only two potentially encountered characters in identifiers:
- ‘@’ which becomes a backtick, which is not used, so no collision here
- ‘_’ which becomes as DEL character ($7f), which is not used, so no collision here
Given than the upper case conversion is meant to be fed to a hash function, and there is no collision, the “or $20” is as good as a proper upper case from an hash code collision point of view!
And it’s branchless, trivial to vectorize and computationally as cheap as it gets.
The only “downside” is that after the previous round of optimization, the case insensitive hash was already no longer anywhere near being a bottleneck in DWScript, so while this implementation is much faster, it has not measurable effect on script compilation… at least for now! 🙂

But this only applies to ANSI characters #0..#127. Many programming languages nowadays support Unicode characters (in particular Umlauts and accented characters) in identifiers.
@Thomas yes that’s right, but that’s for the optimistic code path.
If a character above 127 is encountered, the code fallback to the (far more expensive) Unicode case conversion before running the hash. So if your code has many identifiers with non-ASCII characters, you won’t benefit as much from the optimization, but you would still benefit on all references to library identifiers (classes, functions, etc.) are all those are ASCII.