

 Here are a few findings on Multi-Read Exclusive-Write Synchronizer from a recent upgrade of DWScript‘s GlobalVar functions.
Here are a few findings on Multi-Read Exclusive-Write Synchronizer from a recent upgrade of DWScript‘s GlobalVar functions.
I ran some comparisons between a plain Critical Section, Delphi’s TMultiReadExclusiveWriteSynchronizer and Windows Slim Reader/Writer Lock, of which an implementation was added to the dwsXPlatform unit.
Test Case
Workload consisted of four threads performing a certain amount of read accesses for a one write access. Tests were run on a Delphi XE compiled executable, Windows 2008 R2 quad-core machine.
The CriticalSection case doesn’t discriminate between reads and writes, this was the existing implementation.
The other tests case would attempt to leverage the multi-read single-write aspects.
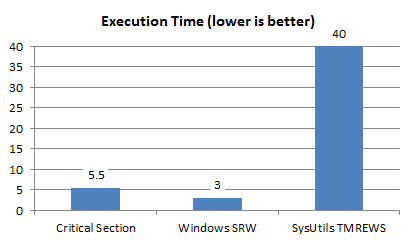 Test Case: 3 reads for 1 write
Test Case: 3 reads for 1 write
- Critical Section: 5.5 seconds
- Windows SRW: 3 seconds
- SysUtils TMREWS: 40 seconds
Test Case: 31 reads for 1 write
- CriticalSection: 5.8 seconds
- Windows SRW: 3.4 seconds
- SysUtils TMREWS: 45 seconds
During the test, CriticalSection usage was hovering just above 50% of 4 cores, Windows SRW was at 100% of 4 cores, and SysUtils TMREWS was using 85% of cores (50% of which being Kernel time).
The slightly longer runtimes in the second case come from reads being slightly more expensive than writes.
TMultiReadSingleWrite
I implemented Slim Read/Write Locks in the TMultiReadSingleWrite class (dwsXPlatform unit), since that API is only available on Vista and above, the class includes a fallback to a plain old Critical Section.
One limitation of the SRW implementation to keep in mind is that it’s not re-entrant, ie. a thread can block itself if it tries to acquire or promote the same lock. This is unlike CriticalSection or TMREWS, which are re-entrant. In practice, this unlikely to be a limiting factor as proper implementations will typically not be re-entrant.
A slightly more problematic limitation is that SRW Locks don’t benefit from dead-lock diagnostics that Windows API Critical Sections benefit from. So if you dead-lock, you’re on your own.
With all those limitations in mind, SRW Locks are indeed slim and fast. Where TMultiReadExclusiveWriteSynchronizer could only be beneficial in extreme-corner cases, SRW Locks will be beneficial in many (most?) scenarios.
Note that the SRW API is loaded and detected in the DWScript implementation “by feature” rather than “by version”, ie. the code checks for the presence of the API, rather than the Windows version.


It is exactly what I found out on my side.
Good old critical sections are doing great for most cases!
But the SRW API is worth considering, when profiling identified a true bottleneck.
My only concern is that SRW is burning 100% of all cores to do its job.
It may be not worth it in most cases.
Critical sections would be slower, but won’t consume all CPU resources, which will still be available for other background process.
Once again, true profiling of the application on production (or at least with world-like data and context) is a need.
SRW is no magic.
You can break your whole application process, just to gain a few ms.
Refactoring the code so that the critical sections are as short and fast as possible, therefore less blocking as possible, is IMHO the best path. Or even switch to another patterns, like Read/Copy/Update or CopyOnWrite, if possible.
Delphi’s TMultiReadExclusiveWriteSynchronizer was a wrong good idea.
Remind me of TMonitor – something built in-house at such a low level is not a good idea.
The OS is doing great such low-level locking, so let the OS do its job!
For short locks, critical section involve spin locks too (100% CPU utilization for a short while), so it’s only for long locks that you can have higher CPU utilization.
At least from Windows 2008 R2, the Windows SRW does relinquish CPU when locked after spin-locking for a short while, so behavior is roughly similar to the Critical Section in that regard (though maybe with different timings).
Read/Copy/Update or CopyOnWrite aren’t always applicable f.i. whenever there is a need for coherency across several variables, or if you need an exact state. They’re also much easier to get wrong.
From a code logic point of view, Critical Sections are the easiest to get right, then RW Locks. I would place Read/Copy/Update last, as there are many ways to end up with stale states, deadlocks and race conditions.
Say any chance that you publish your profiling code?
I would also like it to test against my own home brewn slim mrsw class….
It’s basically a port of the Firebirds db mrsw class…
Hi Eric,
I would like to test you benchmark application… I’ve tested TMultiReadExclusiveWriteSynchronizer against a SRWLock implementation on Win7 (x86/x64) machines with 2 (AMD), 4 (Intel) and 6 (AMD) cores (I will test today in another AMD with 8 cores). I’m using Delphi XE4 compiler and 32 bit application.
I used 2, 4, 8 and 16 reading threads versus 0, 1 and 4 writing threads.
In ALL cases, TMREWS performance was almost identical to SRWLock, and when there are no writing threads, it eventually performed better than SRWLock.
@Alexandre & @Mike Test case is very simple as I wrote in the article, just use TryReadGlobalVar for the read access and WriteGlobalVar for the write access, mix them in threads in a loop (you can find project source there, switch implementations in the dwsGlobalVars unit)
I’m very surprised of your findings could you publish the code you used?
In the source I posted I added two very simple extra test cases for read-only which you claim TMREWS is faster at, in both single and quad threaded flavors, and SRWLock is consistently between 20 and 30 (thirty) times faster than TMREWS here. And for write locks, it’s like 30 to 50 times faster, it’s just not in the same league.
Hi Eric,
After playing a little more with my benchmark, I can confirm that TMREWS is indeed slower thatn SRW and also Critical sections, doesn’t matter the number of writing threads. I didn’t find it 30-50 times slower, though.
These are the typical comparison times I’ve found:
Using: SRW -> Time: 5913
Using: TMultiReadExclusiveWriteSynchronizer -> Time: 16848
Using: TCriticalSection -> Time: 8580
My benchmark application is published on EMB forum in the attachments group:
https://forums.embarcadero.com/thread.jspa?threadID=98007
Great work 🙂
Best regards
@Alexandre You don’t see as much difference because you use “Sleep” as “workload”, it means you relinquish CPU time to other threads, and thus introduces a bias that favors CPU-heavy synchronization objects.
Yes, removing sleep the difference increases. I’ve also included the “famous” TMonitor on it:
Using: TSlimReaderWriter -> Time: 1810
Using: TMultiReadExclusiveWriteSynchronizer -> Time: 11107
Using: TCriticalSection -> Time: 2652
Using: TMonitor -> Time: 39795
TMonitor is “something”!
@Alexandre Yep, it is 🙂 (http://www.delphitools.info/2013/06/06/tmonitor-vs-trtlcriticalsection/)
You’re not in XE5 are you? it’s supposed to have been improved in XE5.
The same benchmark compiled with XE5, running the same workload (4 reader threads, 1 writer thread):
Using: TSlimReaderWriter -> Time: 1763
Using: TMultiReadExclusiveWriteSynchronizer -> Time: 10639
Using: TCriticalSection -> Time: 2980
Using: TMonitor -> Time: 2262
Indeed, TMonitor is much better under XE5. Seems to be better than TCriticalSection now.
If you want a better benchmark, you should introduce some actual workload (like in my case the read/write to a hash map), which will ideally involve some shared state.
Otherwise loop alignment is likely to play a significant role in such tight loops (and Delphi doesn’t align, so which loop is better aligned is essentially random and will vary as the code changes).
@Alexandre Machado
Thank you for the great benchmark. I tried it with my “home brewn” one and here is my result:
CriticalSection: 609
MREW: 1014
Slim: 281
Monitor: 2278
Own (firebird): 468
so not so bad 😉
with a few optmizations I gout my own down to 374
@Eric:
If you like to investigate that code you can download my version from:
http://www.mrsoft.org/Delphi/SyncMultipeReadersOneWriter.pas
(I’m also interested in a few performance comments if you have some 😉