# Mesh World P2P Simulation Hypothesis
By Eric Grange
Last revised 2016-02-25, initial draft 2016-02-18
> If a World Simulation was possible, considerations of efficiency and bandwidth lead us to a decentralized one, which in turn imply very strong constraints on that simulation and observables artifacts. Once hypotheses of symmetry and observer invariance are added, we argue this not only results in speed limit, space-time distortions and Quantum Mechanic-like as observables, but also as inherent technological constraints. Finally, if the simulation device is not upgraded, it leads to further cosmological consequences.
## A. Introduction
If it was possible to run a whole world simulation, would there be observable consequences?
Not just a simulation for an elaborate illusion, but a whole universe.
A huge universe without humanity at its center.
As we know neither the purpose nor the technological means, we will start from a limitedness postulate: the simulation is running with limits... and compromises. The host world, the one where the simulation is being computed is one with limits.
The world simulation hypothesis was first introduced by [Nick Bostrom](http://www.simulation-argument.com/simulation.html), though we asbtract here the considerations related to humanity. A decentralized P2P Simulation hypothesis was first introduced by [Marcus Arvan](http://philpapers.org/rec/ARVTPS). We argue the P2P network topology would be an efficient one, closer to a mesh network, with consequences arising from computing and bandwidth limitations.
### A.1 Device Limits
The simulation is being run by a Device, performing a computation. This Device is limited:
1. The processing capability of the Device's components is limited.
2. The data exchange bandwidth between the Device's components is limited.
We make no particular hypothesis about the host world.
The limitedness above however implies that the Device is submitted to a limitation similar to time, otherwise limits have no meaning. This time may or may not be observer-dependent (like ours), it may be intrinsic or emergent, it is only required in relation to limitedness.
### A.2 Guiding Principles
We will have two guiding principles in our investigation:
1. We are in a normal, statistically more probable case, rather than a special case.
2. Simulation-induced artifacts and singularities are minimal.
The normality principle allows us to accept that if simulating a world like ours is possible, then most worlds like ours are simulations, and if we are not a special case, then we live in one. This is a variation of [Nick Bostrom](http://www.simulation-argument.com/simulation.html)'s argument, without a hypothesis about who or where the simulation is being run.
The second principle is what we will call the "good looking" principle. It means that the simulation is balanced as to minimize simulation-induced effects in the simulated world. Singularities and glitches may exist, but only at the edges and in uncommon settings.
## B. Efficient Simulation
The first consequence of limitedness is that the simulation is an "efficient" one: it is optimized and approximating.
For a given limited simulation capability, it would be possible to run more simulations that are efficient than inefficient ones. So applying the normality principle, if efficient simulations of a world like ours are possible, most simulations will be efficient ones, and we live in an efficient simulation.
This is obviously a balancing act with the good-looking principle. At a minimum, it has to be good looking enough to allow humans in it. However, this does not imply that humans are the target of the simulation. The balancing does not imply intelligent design either.
### B.1 Decentralized
The second consequence of limitedness is that the Device is a decentralized one.
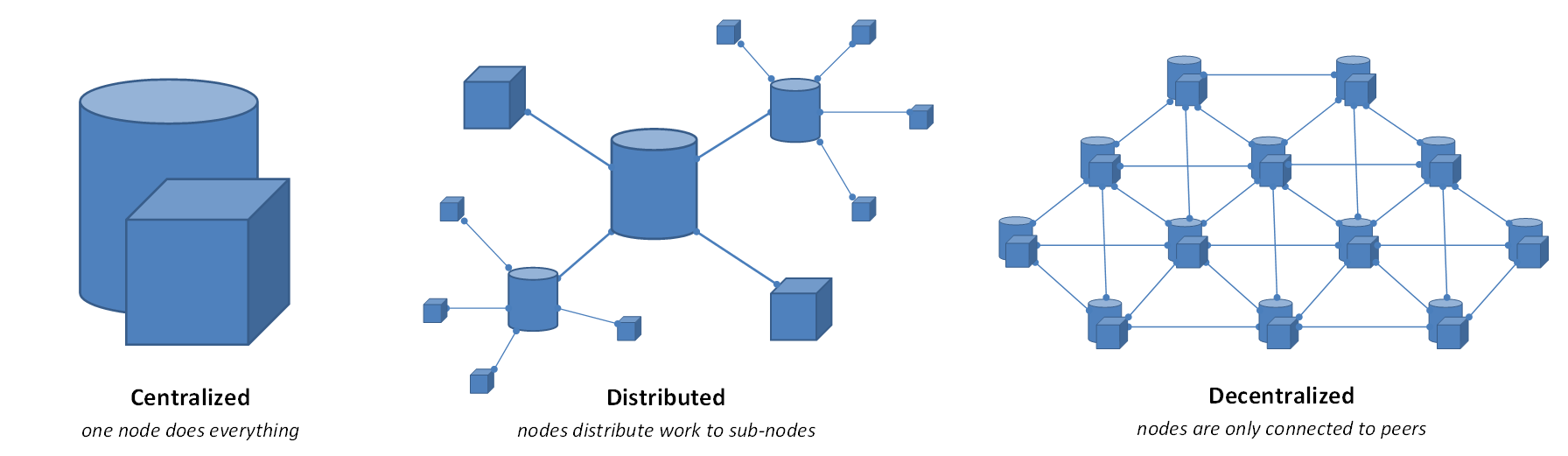
There are only three classes of Device:
1. A centralized Device, which is limited in its capability by the computing capability of the central component.
2. A distributed Device with many slave components, which raises the computing capability drastically. However it is limited by the bandwidth needed to centralize and distribute data.
3. A decentralized Device, which is only limited by the number of components (nodes). Every node adds both its computing capability and bandwidth to peer nodes.
Having a much higher capability for a given set of resources / limits, decentralized Devices would be able to run more simulations. So if decentralized Devices can simulate worlds like ours, then we are living in a simulation run by a decentralized Device.
The decentralized device described here would be a form of peer-to-peer network, with a mesh topology, with intrinsic bandwidth and connectivity limits. Our current peer-to-peer networks usually are decentralized nodes where nodes connect to a subset of the network, but any other node could potentially be connected. In an efficient decentralized Device, the bandwidth would be efficiently used, so saturated, which limits node connectivity. So to speak, there is no more room to run extra wires, no unused frequencies, and no extra capacity for nodes to serve as free-lunch routers. An image could be a human bucket chain, or a human crowd with speech as only mean of data exchange.
However an efficient simulation run by such a decentralized Device will be fundamentally different from those that can be run on distributed or centralized Devices, or even P2P networks where global consensus can be reached.
### B.2 Constraints
The limitedness will manifests itself in *what* a decentralized Device can simulate efficiently, and how it will be simulated.
A decentralized Device has the following properties:
1. It is comprised of an arbitrary number of nodes.
2. Each node can only exchange data directly with neighboring nodes.
Bandwidth limits of the host world restrict the ability of nodes to be connected to all other nodes, at least not without imposing severe limits on the scalability, and thus capability. So we can assume that nodes are only connected to a subset of the Device's nodes, which we will call a "neighborhood".
At the node neighborhood level, a decentralized device can behave like a fully connected peer to peer network.
### B.3 Locality of time
A simulation running on an efficient decentralized Device has no directly accessible central data reference.
Data is processed at the node or neighborhood level, and can only eventually propagate to the whole Device through peer-to-peer exchanges between nodes, then from neighborhood to neighborhood.
At that point we will look at simulation "steps", with "steps" understood in a general meaning of processing, rather than as necessarily discrete or even uniform time steps.
There are two options in terms of simulation steps:
1. The whole Device could wait for a global consensus before proceeding to a next step. The simulation steps would then form a chain, computation branching in graphs then regrouping periodically.
2. Each node could keep forging ahead, without waiting for the others. The coherence of the whole would be only defined through a set of common processing rules.
While allowing a notion of universal simulation time, achieving a global consensus (1) reduces the performance of the whole to that of the slowest nodes and the bandwidth/latency from the farthest nodes. It would be a lot less efficient than the crowd option (2). Hence if simulating our world is possible through option (2), most simulations are bound to be without global consensus, and we live in one.
Various forms of local consensus can be efficient, we are only ruling out global consensus.
Globally shared states become impossible (outside degenerate cases), including time. This is an intrinsic limitation of efficient decentralization, and would be a constraint on any set of simulation rules.
## C. Speed limit
A decentralized simulation is a set of local data states, each evolving locally, and which can only be propagated with technological delays.
To ensure a good looking simulation where the technological limits do not show, the simplest solution would be to introduce a rule in the simulation to arbitrarily limit the propagation speed of simulated states to something the decentralized network of nodes can handle. Make the best of the constraint so to speak.
This limit would have to take into account the amount of data to be transferred, just like propagating one bit of state is not a problem that can be compared to propagating a few terabytes of state.
The bandwidth limit implies that nodes the data is transiting through cannot simultaneously process it, at least not as a coherent whole. The rule should thus lead to a reduced processing workload for data being transferred, as this would be an efficient proposition.
The rule should not be dependent on the origin and destination nodes of the data, and it should not be dependent on what states are described by the data, but only on data volume/complexity and bandwidth requirements. The opposite would make the nodes topology and constraints stand out in the simulation.
Finally, to be good looking such a rule should not be a "hard" singularity wall, but a "softer" wall. Ideally one for which the limit (and singularity) can never be reached. Climbing the asymptote would ideally have to be harder for more complex data, as those are the most problematic in terms of bandwidth and processing.
In summary, this comes down to a requirement of a speed limit for simulated entities, and an invariance of that speed limit for simulated entities.
## D. Data
### D.1 Conservation
Data being lost would not be a good looking property, at least if it is significant enough to force a convergence of the simulation.
Conversely any significant amount of data injection in the simulation could force divergences.
It is thus reasonable to assume that a world-scale simulation would conserve data during processing, i.e. the simulation rules are reversible. To conserve data this reversibility only needs to exist theoretically, it may be impractical.
We can then define data complexity as data having enough information to provide theoretical reversibility of simulation. In the case of a numeric simulation, this reversibility would be theoretical, because affected by numeric precision issues.
The final implication is that data complexity can only be stable or increase as simulation progresses (reduced complexity would be akin to non-reversibility and data loss).
### D.2 Complexity and Entropy
So far we stayed at abstract data complexity levels, but it is time to try and express them in terms of a simulated world like ours.
Complexity in our world is related to mass and/or energy, and under a speed limit, these are equivalent (cf. Special Relativity). These are measures of complexity.
Another form of complexity measure is Entropy, which is related to mass, entropy and space. A notable relation is [Bekenstein bound](http://www.phys.huji.ac.il/~bekenste/PRD23-287-1981.pdf) which provides a maximum entropy for a given mass/energy and a volume of space.
These two forms are estimators of the maximum data and processing complexity. It is conceivable for instance that a set of coherent particles could involve less data complexity than for the same particles in an incoherent state. An efficient simulation would benefit from taking advantage of such coherent states.
However, if the simulated world is chaotic (like ours), it would be impossible to assert how long those coherent states would persist. Complexity could emerge at any time. To avoid processing overload singularities, it would be "safe" to not take into account coherent state optimization in terms of bandwidth and processing balancing, so as to maintain a good looking simulation at all times.
An efficient simulation may however be able to proceed with a reduced "safety margin", while balancing this against good looking properties. Possible simulation artifacts could be a "sudden" (as in singularity) emergence of coherent states from incoherent states.
For the rest of the argument, we will nonetheless consider mass/energy and entropy as good estimators of complexity.
### D.3 Space Distortions
If mass and energy are good indicators of simulation complexity, then all volumes of space are not of similar simulation complexity. Dense volumes in the heart of stars have much more matter than the void of space for instance.
An efficient Device would then have to attribute more computing power to dense areas of space than less dense ones, i.e. more nodes would be needed to handle the volume of space comprising a star than the same volume of space comprised of void.
A consequence is that the mesh of space, the division of simulation space and work between nodes would be irregular in terms of simulation space. Nodes dealing with star simulation would be handling smaller volumes of space than nodes dealing with void.
However the bandwidth considerations that led us to the speed limit apply primarily to the communications between nodes. So data would effectively be transferred differently when going through or near a star than it would when going through void. When going through a star, data would be going through a finer mesh of nodes (more nodes), than when going through void, with larger mesh (less nodes).
An observable consequence of the above would be an apparent distortion of space and distances for regions of high mass and energy. To minimize artifacts, just like for the speed limit, a rule would be required to ensure that bandwidth overload (singularity) is not reached.
In an efficient simulation, the possibility of infrequent singularities could be considered a worthy approximation (optimization). We can introduce here a notion of "safety margin", about which events would be considered rare enough to allow the technology limits of the Device to show through.
The observable consequences of the above being:
1. High data complexity (high energy f.i.) should distort space, even in the absence of significant mass
2. Singularities where the technology limits show through are likely to exist
Of note is that the observable (1) derives not from relativity, but from data complexity considerations. (todo: assess if it comes down to the same math)
The observable (2) comes from the hypothesis that a Device with a lower safety margin would be more efficient, yet still able to simulate a world of our complexity.
## E. Dynamicity
### E.1 Adaptive Space Partition Mesh
As the simulation world is ever changing, an efficient simulation would need an adaptive space partition mesh. This would ensure processing power and bandwidth follow complexity where it goes.
Being a decentralized simulation, such adaptive partitioning would happen at a local node neighborhood level, and would be subject to bandwidth and computing power limits. It would have to propagate, and this would likely result in subtle observables.
Another observable side effect would be that in rapidly changing situations, where data, matter/energy is concentrating, the nodes in the middle of the concentration could possibly be temporarily overloaded. Time anomalies and singularities would thus be more likely, and hopefully observable.
A star collapse could be a possible candidate, but being a relatively common occurrence in our world, it might be well within the safety margin. But larger stars and objects may not be within the safety margins.
Also these anomalies may be more likely to occur for recent events, as the complexity/entropy of the world progresses and may be stretching the Device thin, so to speak.
### E.2 Complexity as simulation progresses
As simulation of a world like ours progresses, the global entropy keeps growing, and so does the simulation complexity. This was also a consequence of data conservation.
In terms of our world, more complex atoms and molecules appear. While stars and planets present coalesced matter, the rest of the world is essentially becoming more and more complex void crisscrossed with more and more waves, blasts, supernova remains, and dust of all kinds.
If the number of nodes of the Device cannot grow at the same pace as the data complexity, it is being faced with ever growing computing needs. At this point there are two options:
1. Slowing down the simulation as a whole. Slowing down as a whole would require a hard rule (shared by all nodes) or a way to propagate the global complexity. It would also not be efficient as not all nodes would be facing the highest complexity.
2. Slowing down the simulation locally. This would of course be a further approximation, and an act of balancing with good looks.
One such approximation could be to devote less computing capability to the empty regions of space. Void would get less computing power and less bandwidth. This would preserve computing power on the denser areas of simulation. Just like the speed limit, this could be set as a rule in the adaptive mesh dynamics.
This would not affect data conservation, but it would have observable consequences in the simulation:
1. Energy or matter crossing vast distances of void would appear slowed down, and more slowed down the more void they crossed.
2. The slowdown effect would increase as simulation progresses, as limited computing power needs to process data of increasing complexity spanning increasing simulation space.
3. The slowdown would have minimal to no effect on complex regions, probably limited to just continuity of the rule.
Such a slowdown would yield insight about the increase in data complexity, though it would require hypothesis about both the mesh adaptiveness and the Device being static or not (upgraded or not).
## F. Device Topology
### F.1 Local Mesh Topology
The limitedness principle implies that each node can only handle a limited complexity, and thus a bounded amount of data, matter and energy. Since density is not uniform, this would translate to a bounded volume of simulation space.
However that still leaves two options:
1. Each node handles an exclusive, strictly bounded volume of simulation space.
2. Each node handles a bounded but overlapping volume of simulation space.
The first option has direct implications on node capability and simulation performance: if workload is not perfectly balanced, nodes could get overloaded quite regularly. This in turns would imply a high safety margin, which would not be efficient.
The overlapping volumes option implies a form of inefficiency and redundancy across neighboring nodes, along with a form of resolution. If all nodes are equal in the local topology, this resolution would be a form of consensus.
This form of resolution by consensus does not need to be submitted to the speed limit. Actually it would be more efficient if it was only partially honoring the speed limit.
The rationale being that if the speed limit exists for large scale bandwidth considerations, honoring it fully at the local level, where bandwidth considerations are not a problem would require extra computing. The speed limit would be honored only for propagation of a consensus resolution.
Two observable consequences of the above would be:
1. Resolution itself could be observed to bypass speed limit, but its consequences could not.
2. Beyond the local consensus distance, the speed limit would not be violated.
The consensus distance would also be expressed in terms of node neighborhood, i.e. it would be distance as distorted by the space-time partition mesh.
The observable (2) would be enforced by the bandwidth limitations, even if the speed limit was somehow bypassed.
### F.2 Local Node Topology
The two ends of the spectrum would be a volume of space large enough to take advantage of statistical processing (as a form of optimization) down to a volume small enough for a cellular automaton.
It could also combine both a low level dedicated technology (like a cellular automaton) with higher level "supervision" for consensus resolution, which is a common approach in our current technology.
At the neighborhood scale, a decentralized Device would behave like a peer to peer network, which has been hypothesized by [Marcus Arvan](http://philpapers.org/rec/ARVTPS).
A cellular automaton interpretation of Quantum Mechanics was published by [Gerard 't Hooft](http://arxiv.org/abs/1405.1548).
Of note that is that a bandwidth limit can emerge as a property of a cellular automaton, with wave propagation like in verlet simulations ([Baraff & Witkin](http://www.cs.cmu.edu/~baraff/papers/sig98.pdf)).
### F.3 Time as an Emerging Simulation Behavior
The rules used in the simulation computation do not need to be time-dependent, they only need to be solvable locally, and they do not need to be realist, only reversible. Actually since time is not universal throughout the Device, it may be preferable in terms of efficiency if the rules were time-independent, and time was an emergent behavior rather than a variable.
Locally is taken as meaning a node neighborhood where consensus is reached, it may involve faster-than-speed-limit resolution, only the consequences of that resolution would be subject to the speed limit.
Realist is taken as meaning computing of data is necessary even when there is no interaction between a data packet and other data packets. In terms of efficiency, not resolving what does not need to be resolved is an obvious optimization.
Of note, [Bell's Theorem](https://en.wikipedia.org/wiki/Bell%27s_theorem) states that no local realist hidden variables can reproduce Quantum Mechanics, under our hypothesis, the simulation would be local, but not fully local (consensus could be superluminal), and might not be realist either.
Finally, there are three times involved here:
1. Time of the host, which appears inaccessible, except as an indirect constraint in the speed limit.
2. Intrinsic time used for the enforcement of the speed limit. For high-level simulation this could be a state variable relative to the last resolution affecting some data. For low-level simulation this could only exist indirectly as accumulated processing.
3. Time for in-simulation observers, which would emerge as a consequence of consensus resolutions.
Time (3) would be an approximation of Time (2), seen not as an arrow of time, but as many small arrows of time in a directed acyclic graph.
### F.4 World Dimensionality
If the world is a simulation on a finite Device, then it could be summarized as a finite amount of information, a one dimensional string of bits.
It could thus be described as a computation on that string of bits, the world would be analogous to a one-dimensional world when seen from the outside. However the locality of computations would make that point of view purely theoretical.
Another description of in-simulation time and reality would be two dimensional: the string of bits in one dimension, and the "previous" or "simultaneous" values of the string of bits in the other dimension. This representation would be slightly more practical in that it can represent the global knowledge locally accessible for computations in a more direct fashion.
Whether this can be related to the holographic principle introduced by [Gerard 't Hooft](https://arxiv.org/abs/gr-qc/9310026) and formalized by [Leonard Susskind](https://arxiv.org/abs/hep-th/9409089) is uncertain at this point (todo).
## G. Cosmology
Under the Big Bang Theory, our world at its beginning was extremely dense, occupying an extremely small volume of space.
Initial simulation conditions would have dominated the data complexity. If data complexity keeps growing, the data then was not as complex as the one we see today. It could even be hypothesized that the complexity was not only minimal, but minimalist, related purely to mass and energy in the world.
A further hypothesis could be made that the initial world was flat in terms of mass/energy density, as that is what a minimal complexity would imply. Heterogeneity in the first instants of our world would then only come from Device imperfections (numerical and propagation issues).
This would lead to a rather uniform appearance of the early universe without invoking inflation, but at the cost of involving "magic" world initialization.
If the previous hypotheses are correct then cosmological expansion rate thereafter would follow data complexity. If defined by emerging complexity, it would follow emergence of large void regions of simulated space and their expansion.
## H. Changelog
* 2016-02-24: added topology diagram
* 2016-02-25: clarified P2P simulation hypothesis relationship, added world dimensionality considerations
## I. References