 Following a recent post by A. Bouchez about an optimized CRC32 hash [1], I took it as an opportunity to re-run a small String Hashing Shootout on the worst hash function collision torture test I know: ZIP codes in UTF-16 (Delphi’s default String format).
Following a recent post by A. Bouchez about an optimized CRC32 hash [1], I took it as an opportunity to re-run a small String Hashing Shootout on the worst hash function collision torture test I know: ZIP codes in UTF-16 (Delphi’s default String format).
Contenders
- CRC32 using the SynCommons CPU implementation (based on Aleksandr Sharahov asm version)
- KR32 hash from SynCommons, based on Kernighan & Ritchie
- FNV1a hash from SynCommons, a canonical implementation of the Fownler-Noll-Vo [2] hash
- SimpleStringHash from dwsUtils, a FNV1a derivative optimized for UTF-16
- BobJenkins hash from Generics.Defaults, the hash you will get with Delphi generics
Benchmark & Results
The benchmark consists in computing a 16 bit hash for all 5 digit numerical zipcodes, measuring the time taken and the number of collisions.
The time below is the lowest value from 30 runs of the benchmark.
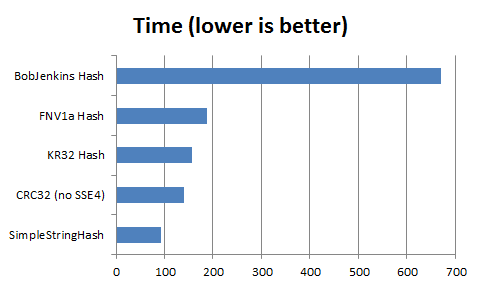
Arnaud reports the SSE4 version to be twice faster if your CPU supports it (mine does not), so it’s same to assume SSE4 CRC32 would be the fastest hash of the benchmark. Though for short strings, brute force performance doesn’t matter too much, unless you’re relying on the Generics’s hash of course.
No for a look at the hash collision, a very important factor for use as the main hash for a hash table. Below are the results, with the collisions normalized as a percentage of a “perfect hash”, ie. a perfect hash would score 100%.
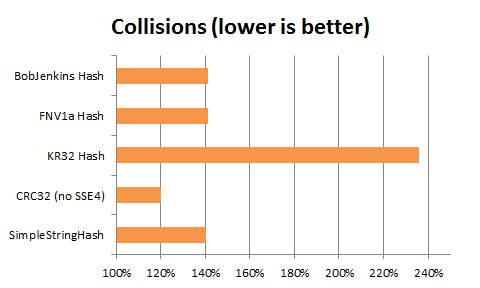
There is one obvious loser: the KR32 function. If you are using it, please just stop. It is both horrible in terms of collisions and not particularly fast.
There is one obvious winner with the CRC32, which pulls quite ahead of the pack, however it is doing a little too good.
The rest of the functions behave quite similarly in a pack, within a 1% spread (BobJenkins being last FWIW).
CRC32 is Too Good?
I tried a few cryptographic hash functions (MDS5, SHA1 & SHA256), they were all much (much) slower, but all got a 140% collisions score. This hints that 140% could be the practical optimum for a generalist hash on that dataset.
So there is definitely an oddity with the CRC32 hashing performance on ZIP codes. On that particular benchmark, it “works for us”, but there are probably cases in which it will not. Which cases those are, I don’t know.
I tried a some other datasets: random data, dictionary words, composed dictionary words… but the oddity did not re-appear.
On those other datasets, the benchmark results were similar: similar performance profile, similar collisions profiles with KR32 being the worst, BobJenkins trailing the pack of the “good” hashe, and cryptographic hashes taking the lead.
But for all of them CRC32 stayed in the middle of the pack in terms of collisions.
Conclusion
While CRC32 the ZIP codes benchmark pointed to an oddity. Other tests did not exhibit weakness, and CRC32 performed very well. But absence of proof of weakness is not proof of absence of weakness 🙂
Findings of good behavior were reproduced by others for other datasets [3].
CRC32 having been designed to be sensitive to 1 bit changes, and the ZIP codes dataset having relatively few changing bits (an UTF-16 zipcode is 80 bits long, but has less than 17 bits of data), it’s possible it is sort of a “best case” for CRC32 as a hash… or it is possible it is a “worst case” for CRC32 as a hash but we got lucky.
Note that there is an old myth about CRC32 not being suitable for hashing, originating in a 2008 paper (now offline [4]), which was later found to be based on a bugged CRC32 test [5]. So the oddity dicussed here is a different one.
Independent benchmarking and testing welcome!