 [This is a guest post, written by Primož Gabrijelčič, www.
[This is a guest post, written by Primož Gabrijelčič, www.
One thing interested me since I started reading Eric’s series on string concatenation performance – how would different memory managers compare in a multi-threaded scenario. Today I decided to spend an hour finding out…
edit 18/11: the tests were run with debug mode, which affected TTextWriter very negatively (TWOBS is also affected a negatively, but less, and StringBuilder and Trivial aren’t affected much). I’ll be repeating tests with more memory managers and in more stable conditions in the next few weeks.
Contenders
Three memory managers were tested. In the first place, there was FastMM – not the built-in version but the latest SourceForge release (4.991).
Next I tested with SynScaleMM, which is part of the mORMot/Synopse.
The last contender was a new memory manager which I’ll call NN. [I’m discussing the possibility of releasing it as an open source with the authors, but for the moment this is a proprietary memory manager.]
Methodology
I took Eric’s source code and wrote a simple console app that generates results for the four tests he used in the multithreaded test and for number of cores from 1 to 12. I have a computer with two Xeon E5-2620 processors, each containing six cores, so 12 threads was a natural limit.
Programs were compiled in XE2 Update 4 Hotfix 1 (my natural habitat) and then I closed all programs running on Windows (7, 64-bit) and ran the tests from the command line.
Besides the time (which was calculated by the Eric’s unit) I have also measured peak working set usage for each memory manager. This gives us a good indication of how much memory each program was using.
Memory Manager Performance
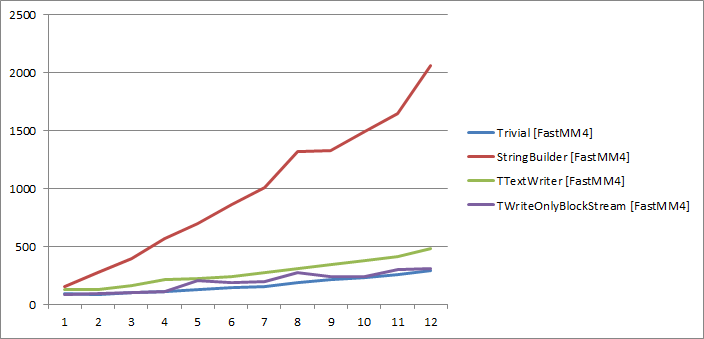
On my hardware (or maybe with my FastMM – I don’t know the exact version Eric was using for his tests), trivial builder performs even better than TTextWriter and TWriteOnlyBlockStream. StringBuilder, however, is terribly slow.
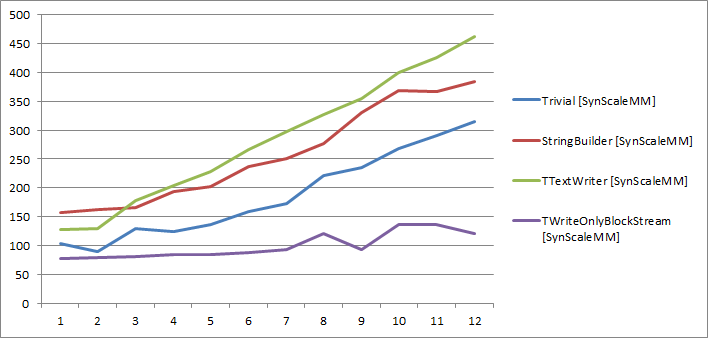
With SynScaleMM, TWriteOnlyBlockStream performs the best. There’s actually almost no slowdown up to the 7 cores (and even the result on 8 cores could be a measurement error). TTextWriter is the slowest and trivial string builder performs better than StringBuilder.
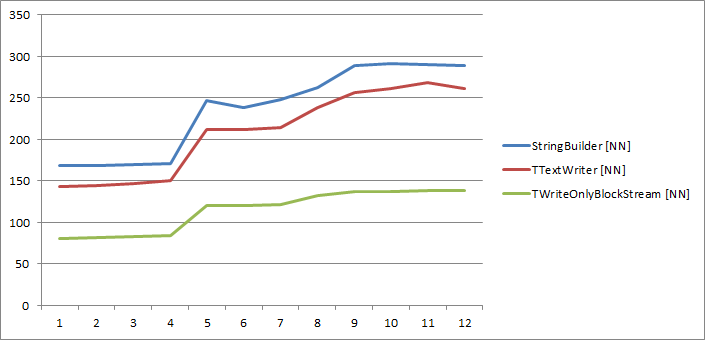
The NN memory manager is, interestingly, the fastest and the slowest of the bunch. As you can see from the graph above, all object-oriented algorithms are performing very well and are not linearly slowing down with the increased number of threads. On the bad side, the trivial algorithm performed so bad that I couldn’t even plot it – it was literally 200 times slower than the FastMM4 version. I have notified the authors about that problem.
Next: Algorithm Performance and Memory Manager [2]
Algorithm Performance and Memory Manager
We get an interesting insight into speed of memory managers if we compare times for one algorithm running on different memory managers.
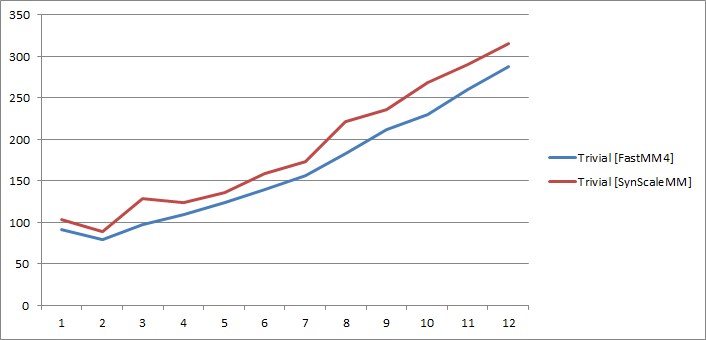
In the trivial case, both FastMM4 and SynScaleMM behave almost the same, while the NN was so slow I couldn’t even show it on the chart.
An interesting observation – in both algorithms two threads performed better than one, which is really a surprise for me as two threads also have to execute (both together) twice as much work. So in a two-thread case, each thread was working faster than in a single thread case.
This is an interesting side-effect of the two processor setup: when a single thread is busy, the OS will tend to switch it across processors to spread the load, and when switched from processor, the L1 and L2 cache are lost, the processor needs to read everything from RAM again. When the one thread is pinned to a processor via its thread affinity, the issue goes away.
For two threads, the OS is apparently smart enough to switch keep one thread on each processor.
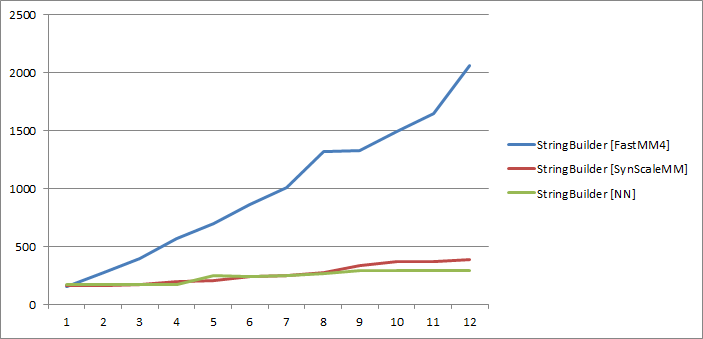
We already know that StringBuilder is performing substandardly with the FastMM, but from this graph we also see that the problem is not that much in the StringBuilder implementation but in the FastMM, where multiple threads are fighting for the same memory manager (because they allocate blocks of the same size). Both SynScalMM and NN are performing well, with NN taking a small lead on >8 cores.
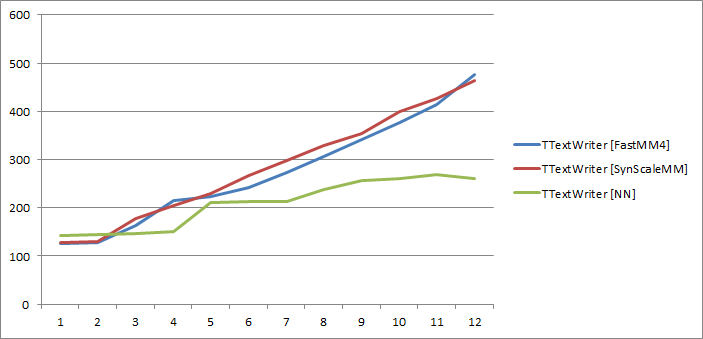
This was in my opinion the most surprising result of the test – not the good performance of the NN, but practically identical performance of FastMM4 and SynScaleMM. It looks that under some circumstances FastMM4 performs quite well even in multithreaded tests.
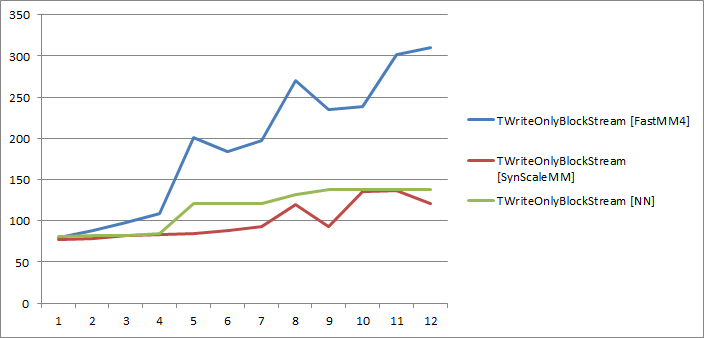
In the last comparison – TWriteOnlyBlockStream – SynScaleMM and NN are performing equally well with SynScaleMM being slightly faster while FastMM4 is about 2,5 times slower. The weird spikes in the FastMM4 graph are probably measurement artifacts.
Previous: Algorithms and Memory Managers [3]
Memory Usage
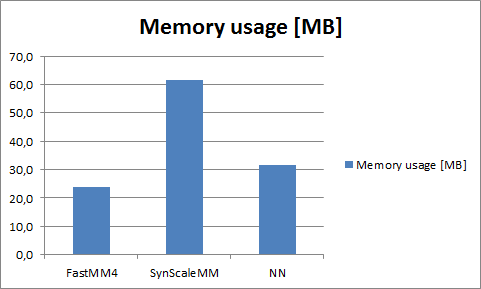
It is also interesting to compare memory usage.
- FastMM4 is the winner here as it only used 23,7 MB.
- SynScaleMM is a big memory hog and it used 61,6 MB.
- NN was using about 50% less than SynScaleMM – 31,5 MB – which is good but still a lot more than FastMM.
Conclusion
So, what to choose? Or, rather, what not to choose.
SynScaleMM can be really fast but uses lots of memory and is, sadly, very unstable. It even managed to crash this simple benchmark once. I would definitely not use it in production.
NN can be very fast but it is also extremely slow while concatenating strings. It will also work only in 32-bit applications because of small parts of assembler sprinkled through the code. Both those deficiencies can be easily fixed once it is released as open source.
For the time being I’ll stick with FastMM. It also has the best debugging capabilities of them all.
My dream scenario? Make NN open source and then convince Pierre to run a Kickstarter to finance integrating good features of NN into FastMM4 (which could then probably be called FastMM5). I know I would cash out few hundred bucks to see this happen.